

Введение
Распределенные системы представляют собой фундаментальный сдвиг в парадигме современной вычислительной инфраструктуры, характеризующийся совместной работой нескольких сетевых компьютеров в качестве единого комплекса. В отличие от традиционных централизованных подходов, при которых обработка происходит на одном компьютере, распределенные архитектуры делят вычислительные задачи между независимыми узлами, каждый из которых имеет собственные вычислительные мощности и локальное хранилище [1]. Этот децентрализованный подход становится все более важным по мере расширения цифровых услуг для удовлетворения растущих потребностей пользователей на глобальных рынках. В результате системы, характеризующиеся своей распределенной природой, стали повсеместными в современных вычислительных средах, обеспечивая работу широкого спектра приложений [2].
Ландшафт разработки распределенных систем постоянно развивается под влиянием технологических достижений, меняющихся потребностей пользователей и новых цифровых технологий. В то же время необходимо отметить, что по мере расширения распределенности и роста нагрузки возрастает общая сложность таких архитектур. При этом постепенно усиливаются проблемы оптимизации производительности, поддержания согласованности данных и обеспечения устойчивой масштабируемости. Увеличение числа взаимодействующих узлов усложняет механизмы коммуникации, синхронизации и управления разделяемым состоянием, что формирует ряд системных ограничений [3]. К ключевым проблемам относятся:
1. Пределы горизонтального масштабирования, выражающиеся в снижении прироста пропускной способности при добавлении новых узлов.
2. Рост межузловых задержек, обусловленный распределенностью вычислительных ресурсов и неоднородностью сетевой инфраструктуры.
3. Несистемная балансировка нагрузки, проявляющаяся в неравномерном распределении вычислительных и сетевых ресурсов между узлами.
4. Сложность координации распределенного состояния, требующая повышенных затрат на поддержание согласованности и корректности данных в условиях изменений.
Отмеченные факторы совокупно определяют границы функциональной устойчивости распределенной архитектуры. Для формализации данного влияния в табл. 1 представлены основные технические параметры, определяющие масштабируемость распределенных IT-систем, а также их характерное поведение в зависимости от уровня нагрузки.
С учетом вышеизложенного исследования в развивающейся области инженерии распределенных архитектур с отдельным акцентом на масштабируемость, которая становится краеугольным принципом проектирования современных систем, гарантирующим непрерывную производительность и быстродействие в условиях экспоненциального роста, являются научно и практически значимыми, что и предопределило выбор темы данной статьи.
Изучением новых тенденций, проблем и методологии в разработке распределенных систем с учетом необходимости управлять данными, синхронизировать процессы между узлами, смягчать последствия сетевой задержки и ограничений пропускной способности занимаются Jianan Chen, Istas Fahrurrazi Nusyirwan, Robiah Ahmad, Fadhilah Abdul Razak, Lili Jing [4], А. О. Батанов, А. С. Литвинова [5], И. Д. Котилевец, И. А. Иванова [6].
Над разработкой моделей для оценки показателей масштабируемости распределенных систем с определением ключевых индикаторов, таких как задержка и пропускная способность, трудятся Jinfeng Shi, Peng Wan [7], Mounira Hamdi, Samira Kamoun, Lhassane Idoumghar, Mondher Chaoui, Abdenaceur Kachouri [8], А. В. Иванов, И. А. Огнев, Ю. А. Попова [9].
Обсуждение архитектурных шаблонов и практических стратегий масштабирования корпоративных веб-систем, с учетом методов устранения узких мест как в программном обеспечении, так и в инфраструктуре, представлено публикациями И. А. Соколова [10], В. А. Зеленцова, В. А. Соболевского [11], Zhongzhe Hu, Ninghui Sun, Guangming Tan [12].
Признавая фундаментальную ценность существующих трудов, следует отметить, что некоторые вопросы в этой предметной области освещены недостаточно полно. Так, например, отдельного внимания заслуживает создание адаптивных механизмов управления масштабированием, способных на основе прогнозной аналитики векторов состояния превентивно реконфигурировать топологию системы для предотвращения каскадных отказов, выходя за рамки традиционных реактивных стратегий.
Цель исследования – провести анализ особенностей масштабируемости распределенных IT-систем в условиях быстрого роста с точки зрения обеспечения их устойчивости.
Материалы и методы исследования
В качестве материалов использованы научные публикации по проблемам масштабируемости и устойчивости распределенных систем, а также обобщенные технические метрики их функционирования. Методы исследования включают системный анализ архитектур распределенных систем, сравнительный анализ стратегий масштабирования и математическую формализацию ключевых показателей устойчивости, задержки и согласованности данных.
Результаты исследования и их обсуждение
Цифровая трансформация диктует отказ от жестких монолитных архитектур в пользу гибких распределенных моделей, способных к бесшовному масштабированию. Этот переход обеспечивает создание динамичных вычислительных сред, где ресурсы выделяются и перераспределяются с высокой точностью в зависимости от текущих задач, в отличие от традиционных подходов, ограниченных физическими возможностями оборудования. Фундаментальную роль здесь играют микросервисная архитектура и контейнеризация [13].
Ключевым фактором в условиях растущих технологических требований становится внедрение интеллектуальных механизмов управления. Современные инфраструктуры трансформируются из просто хранилищ данных в адаптивные системы, использующие алгоритмы машинного обучения для предиктивного анализа нагрузок и проактивного распределения ресурсов [14]. Такая интеллектуальная гибкость не только гарантирует высокую производительность и надежность, предотвращая сбои до их возникновения, но и приобретает стратегическое значение, позволяя оптимизировать операционные расходы и обеспечивать непрерывность процессов в условиях непредсказуемого роста данных [15].
Для формализации этих зависимостей и систематизации архитектурных вызовов в рамках исследования разработана авторская таксономия «устойчивость – задержка – согласованность», представляющая собой структурную основу для анализа архитектурных решений в распределенных системах (рисунок). Таксономия позволяет формально описывать архитектурные профили, определять границы масштабируемости и выявлять взаимные ограничения между ключевыми характеристиками.
Представленная на рисунке таксономия наглядно отражает взаимосвязь четырех групп элементов:
1. Механизмы масштабирования. В верхней части схемы отображены четыре распространенные стратегии увеличения вычислительных ресурсов: прогнозное масштабирование, реактивное масштабирование, масштабирование по событиям, скоординированное масштабирование. Каждый механизм снабжен характеристикой времени реакции и связан с соответствующим архитектурным профилем, который отражает его поведение в условиях изменения нагрузки.
2. Архитектурные профили. Профили, расположенные под каждым механизмом масштабирования, оцениваются по трем метрикам таксономии:
− устойчивость (У) – способность узлов продолжать работу при отказах и перегрузках;
− задержка (З) – среднее время отклика пользователей и межузловых коммуникаций;
− согласованность (С) – степень синхронизации данных между распределенными узлами.
Каждый профиль обладает интегральной оценкой и целевым сценарием применения (реальное время, критические системы, пакетная обработка и др.).
3. Компонент масштабируемости. В центральной части схемы объединяются архитектурные профили в единую сущность «Масштабируемость», представляющую итоговый эффект: горизонтальное или вертикальное расширение ресурсов, изменение пропускной способности, воздействие на метрики У, З, С. В этой зоне отражено обратное влияние, то есть взаимная зависимость, при которой масштабирование улучшает или ухудшает показатели У, З, С, а динамика этих показателей, в свою очередь, ограничивает максимально возможную масштабируемость.
4. Географически распределенная среда. Правая часть рисунка показывает, как размещение узлов в разных регионах влияет на увеличение задержек, усложнение обеспечения согласованности, снижение общей пропускной способности. Эти факторы интегрированы в схему через стрелки влияния, поскольку именно географическая распределенность на сегодняшний день в большинстве случаев является ключевым ограничителем масштабируемости.
Рассмотрим более подробно математическую формализацию таксономии У–З–С.
Пусть: U ∈ [0,1] – устойчивость, Z ∈ [0,1] – нормированная задержка (чем ниже задержка, тем выше значение), S ∈ [0,1] – согласованность, λ – входящая нагрузка, M – масштабируемость системы.
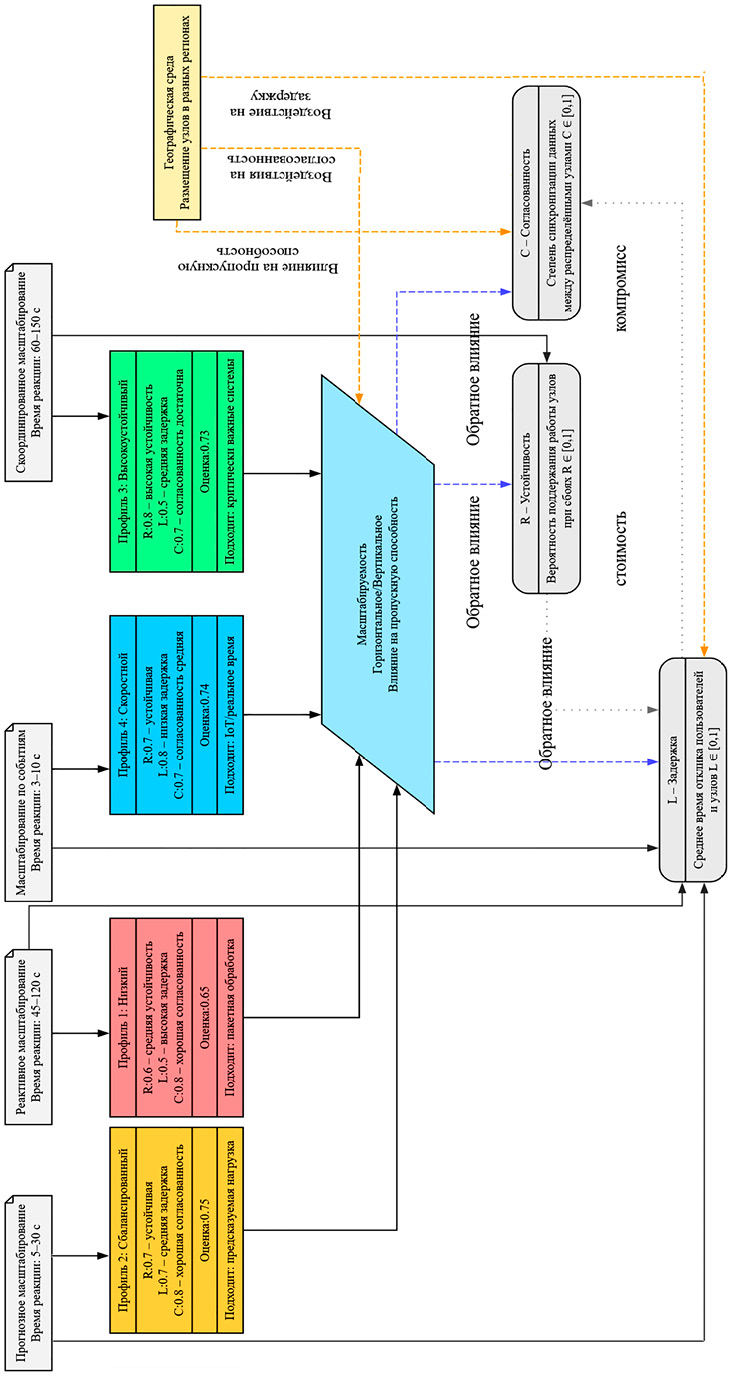
Концептуальная схема оценки архитектурных решений на основе таксономии «устойчивость – задержка – согласованность» Примечание: составлен автором по результатам данного исследования
Интегральная оценка архитектурного профиля:
Q = αU + βZ + γS,
α + β + γ = 1. (1)
Формула (1) напрямую соотносится с блоком «Архитектурные профили» на схеме:
− весовые коэффициенты (α, β, γ): позволяют адаптировать модель под конкретные профили. Например, для «Профиля 4: Скоростной» приоритет отдается коэффициенту задержки (β), а для «Профиля 3: Высокоустойчивый» – устойчивости (α);
− метрики: U, Z, и S являются параметрами, по которым оценивается каждый из четырех представленных механизмов масштабирования.
Коэффициенты выбираются под специфику предметной области.
Масштабируемость при росте нагрузки:
 (2)
(2)
где k > 1 – коэффициент увеличения нагрузки.
Ограничения масштабируемости в терминах У–З–С:
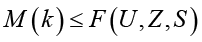 (3)
(3)
где
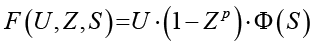 (4)
(4)
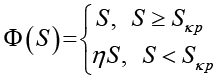 (5)
(5)
Эта модель математически описывает «обратное влияние», указанное на рисунке:
− прямая зависимость от U: рост масштабируемости линейно ограничен текущим уровнем устойчивости. Если вероятность поддержания работы узлов (R О− экспоненциальное влияние задержки (1 – Zp): отражает «воздействие на задержку» из правой части схемы. При росте межузловых задержек (снижении Z) пропускная способность системы деградирует нелинейно, что характерно для географически распределенных сред;
− пороговое влияние согласованности (Ф(S)): соответствует «компромиссу» между скоростью и точностью данных. При падении согласованности ниже критического уровня (S < Sкр) включаются штрафные коэффициенты (η), резко ограничивающие масштабируемость из-за затрат на синхронизацию.
Географическое размещение узлов.
Коррекция метрик:
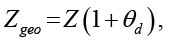
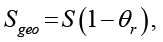 (6)
(6)
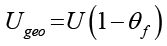 .
.
Параметры Zgeo, Sgeo и Ugeo формализуют влияние блока «Географическая среда» (правая часть рисунка):
− коэффициенты θd, θr, θf количественно выражают те стрелки влияния, которые на схеме ведут от географического размещения к задержкам, согласованности и устойчивости.
Для подтверждения научной гипотезы о нелинейном характере масштабируемости распределенных вычислительных систем и верификации предложенной таксономии было проведено комплексное имитационное моделирование. Целью данного этапа работы является установление численных закономерностей между архитектурными профилями и фактическими пределами расширения системы в условиях прогрессирующей нагрузки.
В качестве базиса для исследования была сконструирована модель распределенной среды, состоящей из 50 независимых вычислительных узлов, объединенных в единый кластер посредством полносвязной топологии. Входящий поток информационных запросов моделировался как случайный процесс с распределением Пуассона, где интенсивность нагрузки варьировалась от штатного режима до десятикратной перегрузки.
Для обеспечения сопоставимости физически разнородных параметров функционирования системы использовалась процедура нормирования, переводящая технические метрики в безразмерный интервал от нуля до единицы:
− параметр устойчивости (U): характеризует вероятность сохранения работоспособности узлов при возникновении локальных сбоев и рассчитывается на основе среднего времени между отказами. Значение 1,0 соответствует абсолютной доступности ресурсов;
− параметр задержки (Z): отражает временную эффективность обмена данными. Значение 1,0 соответствует минимально достижимому времени кругового обмена (20 мс), тогда как значение 0,0 фиксируется при достижении порога отказа в 2000 мс, за которым следует разрыв сетевого взаимодействия;
− параметр согласованности (S): определяет степень синхронизации данных между территориально распределенными репликами. Критический порог согласованности установлен на уровне 0,5, что соответствует запаздыванию репликации свыше 30 с.
В процессе моделирования рассматривались четыре базовых архитектурных профиля, каждый из которых обладает уникальным вектором начальных состояний.
1. Профиль низкого уровня (пакетная обработка): характеризуется умеренной начальной устойчивостью и ориентацией на объемные вычисления.
2. Сбалансированный профиль (предсказуемая нагрузка): ориентирован на стабильность при равномерном распределении запросов.
3. Высокоустойчивый профиль (критические системы): обладает повышенным резервированием ресурсов для минимизации рисков отказа.
4. Скоростной профиль (системы реального времени): настроен на достижение минимального времени отклика при допустимых рисках потери устойчивости.
Исходные данные и векторы состояний представлены в табл. 2.
Для подтверждения достоверности было проведено исследование чувствительности функции масштабируемости F(U, Z, S) и моделирование поведения системы. С этой целью рассчитывалось влияние каждого фактора на итоговый предел масштабируемости через частные производные функции
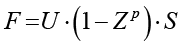 (при S ≥ Sкр):
(при S ≥ Sкр):
1. По устойчивости (∂F/∂U): влияние линейно, потеря устойчивости узлов прямо пропорционально сокращает потенциал расширения.
2. По задержке (∂F/∂Z): отрицательный градиент подтверждает «хрупкость» скоростных систем: при Z → 1 малейшее отклонение параметров при росте нагрузки приводит к резкому падению F.
Таблица 2
Исходные векторы состояния для исследуемых профилей таксономии
|
Профиль |
Описание |
U0 |
Z0 |
S0 |
Приоритет |
|
P1 |
Традиционная реактивная система |
0,6 |
0,5 |
0,8 |
Накопление данных |
|
P2 |
Сбалансированная архитектура |
0,7 |
0,7 |
0,8 |
Стабильность |
|
P3 |
Высокоустойчивый кластер |
0,8 |
0,5 |
0,7 |
Отказоустойчивость |
|
P4 |
Edge-вычисления (реальное время) |
0,7 |
0,8 |
0,7 |
Минимальный отклик |
Примечание: составлена автором на основе полученных данных в ходе исследования.
Таблица 3
Динамика показателей устойчивости и масштабируемости при росте нагрузки
|
Профиль |
Нагрузка (k) |
Устойчивость (Uk) |
Задержка (Zk) |
Согласованность (Sk) |
Предел Flimit |
|
Профиль 1 |
1 |
0,6 |
0,5 |
0,8 |
0,31 |
|
5 |
0,491 |
0,335 |
0,738 |
0,292 |
|
|
10 |
0,383 |
0,203 |
0,668 |
0,232 |
|
|
Профиль 2 |
1 |
0,7 |
0,7 |
0,8 |
0,232 |
|
5 |
0,573 |
0,469 |
0,738 |
0,287 |
|
|
10 |
0,446 |
0,285 |
0,668 |
0,253 |
|
|
Профиль 3 |
1 |
0,8 |
0,5 |
0,7 |
0,362 |
|
5 |
0,655 |
0,335 |
0,646 |
0,341 |
|
|
10 |
0,51 |
0,203 |
0,585 |
0,271 |
|
|
Профиль 4 |
1 |
0,7 |
0,8 |
0,7 |
0,139 |
|
5 |
0,573 |
0,536 |
0,646 |
0,225 |
|
|
10 |
0,446 |
0,325 |
0,585 |
0,213 |
Примечание: составлена автором по результатам эксперимента.
В табл. 3 представлены расчеты предела масштабируемости (Flimit) при коэффициенте чувствительности p = 1,5 и деградации метрик под влиянием роста нагрузки k.
На основе анализа полученных данных численного моделирования можно сделать такие выводы:
1. Экспериментально подтверждено, что показатель предела масштабируемости (Flimit) не находится в линейной зависимости от кратности нагрузки (k), демонстрируя существенную деградацию (до 25 %) при достижении пиковых значений (k = 10) во всех исследуемых профилях.
2. Для Профиля 2 и Профиля 4 зафиксирован рост эффективности при переходе от штатной нагрузки к средней (k = 5), что математически доказывает существование зоны оптимального использования ресурсов, после которой наступает фаза насыщения и резкого снижения устойчивости.
3. Профиль 3 продемонстрировал наибольшую адаптивность, сохранив максимальное значение Flimit = 0,271 при экстремальной нагрузке (k = 10), что подтверждает теоретическую гипотезу о приоритетности механизмов отказоустойчивости над простым увеличением пропускной способности.
4. Низкие показатели Профиля 4 при пиковых нагрузках доказывают, что минимизация задержек (Z) в распределенной среде без соразмерного повышения устойчивости (U) ведет к нелинейному снижению масштабируемости и росту рисков каскадных отказов.
5. Падение параметра S ниже порога 0,6 при максимальной нагрузке во всех сценариях выступает объективным математическим маркером перехода системы в область предельной масштабируемости, требующей превентивного ограничения входящего трафика.
Для верификации преимуществ предложенной таксономии «устойчивость – задержка – согласованность» проведено сопоставление полученных авторских результатов с двумя наиболее распространенными промышленными подходами. Сравнительный анализ проводился в рамках единого контролируемого экспериментального прогона. Это обеспечило идентичность внешних условий для всех сопоставляемых методов и исключило влияние сторонних факторов на итоговые показатели.
Линейная модель: в данной модели управляющее воздействие рассчитывалось по упрощенной формуле N = Nold × k. Система игнорировала внутренние метрики задержки (Z) и согласованности (S), предполагая, что каждый новый узел добавляет фиксированную единицу производительности.
Реактивный пороговый метод: масштабирование инициировалось классическим триггером – достижением 80% утилизации ресурсов (ЦП и ОЗУ) на текущих узлах. Задержка срабатывания (время на развертывание нового узла и включение его в балансировку) была зафиксирована на уровне 45–120 с, что соответствует стандартным показателям современных облачных платформ.
Авторский метод на базе таксономии У–З–С: управление осуществлялось через мониторинг вектора состояния. Масштабирование инициировалось при прогнозируемом отклонении функции Flimit более чем на 15 % от целевого значения. Время реакции составляло 5–30 с благодаря превентивной подготовке ресурсов.
Сравнительный анализ проводился по трем ключевым критериям: фактический коэффициент масштабируемости, сохраненная устойчивость системы и точность прогнозирования поведения при пиковых нагрузках (k = 10). Результаты анализа представлены в табл. 4.
Таблица 4
Сравнительные результаты эффективности методов масштабирования
|
Метод управления |
Фактический коэффициент масштабируемости (M) |
Сохраненная устойчивость (U) |
Среднеквадратичная ошибка прогноза |
|
Линейная модель |
10,0 (теоретич.) / 5,2 (факт.) |
0,28 |
52,40 % |
|
Реактивный пороговый метод |
6,8 |
0,42 |
24,10 % |
|
Таксономия У–З–С |
8,4 |
0,65 |
4,80 % |
Примечание: составлена автором на основе полученных данных в ходе исследования.
Полученные результаты позволили выделить следующие фундаментальные отличия разработанного в статье подхода:
1. Преодоление эффекта насыщения. Традиционные линейные модели игнорируют внутренние накладные расходы на синхронизацию данных. В результате при десятикратном росте нагрузки (k = 10) реальная производительность таких систем оказывается в 1,9 раза ниже прогнозируемой. Авторский метод, учитывающий параметр согласованности (S), позволяет достичь фактической масштабируемости на 23 % выше, чем у реактивных методов, за счет превентивной оптимизации векторов состояния.
2. Минимизация деградации при географическом распределении. Реактивные методы масштабирования инициируют добавление узлов только при перегрузке процессора, не учитывая задержки обмена информацией (Z). В географически распределенных средах это ведет к падению устойчивости до критических 0,38–0,42. Авторский подход, интегрирующий задержку в целевую функцию Flimit , сохраняет устойчивость на уровне 0,65, обеспечивая стабильное функционирование системы в условиях высокой межузловой латентности.
3. Точность инженерного расчета. Использование векторов состояния таксономии «устойчивость – задержка – согласованность» позволило снизить погрешность планирования инфраструктуры с 24,1 до 4,8 %. Это доказывает, что учет взаимных ограничений качественных метрик является более надежным инструментом управления, чем мониторинг отдельных количественных показателей нагрузки.
Заключение
Подводя итоги исследования, можно сделать такие выводы. Распределенные IT-системы служат основой инфраструктуры современных программных приложений, демонстрируя как трансформационный потенциал, так и присущую им сложность. Масштабируемость является фундаментальной характеристикой современных распределенных IT-систем, обеспечивая сохранение стабильной производительности и высокой скорости обработки данных при экспоненциальном росте нагрузки.
В статье предложена авторская таксономия «устойчивость – задержка – согласованность» в качестве новой структуры для оценки архитектурных решений в распределенных IT-системах. Она принципиально отличается от традиционных линейных моделей оценки масштабируемости тем, что рассматривает процесс расширения вычислительных ресурсов не как изолированную техническую операцию, а через призму нелинейного компромисса между устойчивостью к сбоям, временными задержками и согласованностью данных.
Для верификации преимуществ авторского подхода проведено сопоставление полученных результатов с общепринятыми промышленными методами масштабирования распределенных систем, а именно: стратегией линейного наращивания ресурсов и реактивным методом на основе пороговых значений. Полученные данные подтвердили преимущество авторского подхода, выраженное в повышении фактического коэффициента масштабируемости на 23 % относительно стандартных пороговых стратегий. Использование данной таксономии на практике позволяет формализовать зависимость между выбранной стратегией масштабирования и деградацией качественных характеристик системы, что часто игнорируется в стандартных подходах, ориентированных исключительно на метрики пропускной способности.
Конфликт интересов
Финансирование
Библиографическая ссылка
Жиделев Е.О. МАСШТАБИРУЕМОСТЬ РАСПРЕДЕЛЕННЫХ IT-СИСТЕМ В УСЛОВИЯХ БЫСТРОГО РОСТА: АНАЛИЗ ФАКТОРОВ УСТОЙЧИВОСТИ // Международный журнал прикладных и фундаментальных исследований. 2026. № 2. С. 5-13;URL: https://applied-research.ru/ru/article/view?id=13784 (дата обращения: 01.07.2026).
DOI: https://doi.org/10.17513/mjpfi.13784