
Scientific journal
International Journal of Applied and fundamental research
ISSN 1996-3955
ИФ РИНЦ = 0,556
SYSTEMS OF SCIENTIFIC RECOMMENDATIONS

Главное предназначение систем рекомендаций заключается в поддержке навигации целевого пользователя по сложному информационному пространству. В основе выработки рекомендаций находится совокупность знаний системы о пользователе, других пользователях в системе, и самого информационного пространства. Все системы используют информацию о пользователе (иногда называемую профилем пользователя, пользовательской моделью или пользовательскими настройками) для формирования рекомендаций. Примерами научных рекомендательных систем являются реферативные системы, рекомендательные системы подбора рецензентов, цитатные рекомендательные системы и системы рекомендаций по научным статьям и журналам [12].
Проблема выработки рекомендаций применительно к научным объектам (например, научным статьям, журналам, научным сотрудникам) существенно отличается от традиционных рекомендательных задач по потребительским товарам или фильмам. Контент-ориентированные подходы, основанные на анализе содержимого, используют при определении соответствия предпочтениям потенциальных объектов, в основном, ключевые слова или фразы из предметной области, игнорируя при этом семантические связи (например, соавторство и цитирование).
Предметом перспективных исследований в области рекомендующих систем являются модели, объединяющие предметные и семантические аспекты в единую инфраструктуру [3]. Одним из эффективных методов выявления социальных связей между исследователями является кластер-анализ, основанный на сегментации тематических интересов.
Рекомендательная система подбора рецензентов фокусируется на поиске соответствующих рецензентов для научных документов. Рекомендательная система научных статей ориентирована на подбор специализированных научных документов для исследователей. Цитатные рекомендательные системы, анализируя содержание основного текста, подбирают релевантные запросу цитаты [10].
Подходы, применяемые в современных рекомендательных системах для научных исследований, могут быть объединены в три группы [2]:
– подходы, основанные на анализе содержимого;
– методы коллаборативной фильтрации;
– гибридные методы.
Контент-ориентированные подходы
Контент-ориентированные подходы сосредотачивают внимание на сопоставлении текстовых документов с точки зрения близости ключевых слов и используют несколько методов, в том числе латентный семантический анализ (ЛСА) [5,9,13], векторная модель семантики (VSM) [0].
Контент-ориентированные методы для выработки рекомендаций используют информацию от самих объектов.
Для данных методов можно привести некоторые характеристики:
– предопределенные представление и организация документов;
– представление текущих интересов пользователя;
– наличие стадии сравнения, результатом которой является набор соответствующих документов;
– наличие стадии оценки выбранных документов;
– динамический характер интересов пользователя.
Интересы пользователя представляются в виде запросов, состоящих в большинстве случаев из ключевых слов, описывающих потребности пользователя.
В дополнение к указанным характеристикам следует отметить некоторые другие важные аспекты:
– выдача соответствующих документов может быть произведена как из статического корпуса, так и постоянно меняющегося корпуса;
– ранжирование документов может быть выполнено как по релевантности, так и по времени создания;
– запрос может быть сохранен в информационной модели пользователя.
Общими чертами всех моделей, используемых в контент-ориентированных рекомендательных системах, являются индексация и классификация содержимого каждого документа в корпусе документов. Приведем краткие описания трех моделей.
Модель логического поиска
В модели логического поиска пользовательский запрос может состоять из нескольких подзапросов (терминов), соединенных логическими операторами. Это модель «с точным соответствием», в которой терминам запроса должны соответствовать термины, найденные в соответствующих документах. Эта модель не предусматривает ранжирования релевантности.
Векторная модель
В векторной модели документ моделируются как вектор в многомерном векторном пространстве терминов [1]. Каждому измерению пространства соответствует термин из корпуса документов. Значение каждой из компонент вектора документа равно оценке TFIDF важности термина в тексте документа, которую можно определить следующим образом.
Обозначим TF (term frequency) – это нормализованная частота слова в тексте, которая определяется по формуле
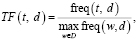 (1)
(1)
где 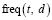 – количество слов t в документе d. Величина TF принимает значения из отрезка [0,1].
– количество слов t в документе d. Величина TF принимает значения из отрезка [0,1].
Пусть 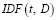 – обратная частота документов (inverse document frequency).
– обратная частота документов (inverse document frequency).
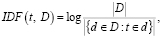 (2)
(2)
где 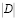 – количество документов в наборе,
– количество документов в наборе, 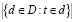 – количество документов, в которых встречается слово t.
– количество документов, в которых встречается слово t.
Искомая оценка TFIDF вычисляется как произведение TF на IDF.
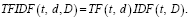 (3)
(3)
Сходство между документами можно оценить с помощью вычисления косинуса угла между векторами.
Вероятностная модель
В вероятностных моделях в качестве меры релевантности запроса к различным документам используется вероятность. Для этого строится байесовский классификатор, который должен предсказать вероятность того, что страница pj принадлежит к классу Ci (т.е. является важной или неважной) исходя из ключевых слов 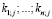 на этой странице.
на этой странице.
Методы коллаборативной фильтрации
Традиционные методы коллаборативной фильтрации, используемые в научных рекомендательных системах, точно предсказывают предметы интереса для активного пользователя, основываясь на ранее известных предпочтениях похожих пользователей. Более точно основное предположение формулируется следующим образом: пользователи, которые ранее имели похожие мнения по вопросам в некоторой предметной области, в будущем будут также иметь схожие мнения. В рекомендательных системах, основанных на коллаборативной фильтрации, организуется сбор мнений пользователей об объектах. Эта информация хранится в матрице рейтингов. Например, можно построить три различных рейтинговых матрицы: автор-цитирование, статья-цитирование, и цитирование-цитирование. Отметим, что часто возникает ситуация, когда матрица рейтингов оказывается разреженной. В этом случае значения нулевых элементов матрицы рейтингов активного пользователя заменяются совокупными рейтингами объектов, построенными на основании информации, полученной от других пользователей. Для этого в системе организуется поиск k пользователей, наиболее похожих на активного пользователя, и которых будем именовать соседями. Совокупные рейтинги соседей предполагается использовать в качестве рекомендаций для активного пользователя.
Существует несколько методов вычисления сходства между двумя пользователями [7,11]. Наиболее часто используется метод с использованием корреляции Пирсона. Для активного пользователя a и другого пользователя u корреляция Пирсона 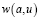 определяется по формуле
определяется по формуле
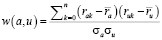 , (4)
, (4)
где суммирование выполняется по всем объектам с рейтингами от пользователей a и u; 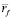 – средний рейтинг пользователя f;
– средний рейтинг пользователя f; 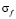 – стандартное отклонение рейтинга пользователя f.
– стандартное отклонение рейтинга пользователя f.
На основе сходства между всеми пользователями отбираются k наиболее похожих на активного пользователя с дальнейшим объединением их рейтингов. Для этого формируется набор элементов, у которых присутствуют рейтинги соседей и у которых отсутствуют рейтинги активного пользователя. Совокупный рейтинг 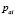 для активного пользователя a и объекта i из полученного набора определяется по формуле
для активного пользователя a и объекта i из полученного набора определяется по формуле
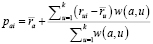 , (5)
, (5)
где суммирование выполняется по всем k соседям пользователя a.
Очевидно, что данные методы являются менее эффективными в случае недостаточного числа оценок от других пользователей.
Использование методов коллаборативной фильтрации эффективно для выработки рекомендаций по статьям, цитатам и при поиске экспертов.
Гибридный подход
Гибридный подход предусматривает сочетание контент-ориентированных методов и коллаборативной фильтрации. Комбинирование методов позволяет избежать ограничений, свойственных каждому подходу. Например, Хванг и Чжуан [8] предложили подход, сочетающий информацию о содержании статьи и информацию об интернет-активности её использования, для выработки рекомендаций в контексте цифровой библиотеки. Хе и др. [0] создали интегральную модель, комбинирующую лингвистическую модель с анализом цитируемости, для получения рекомендаций относительно цитат для научно-исследовательских работ.
Заключение
В данной работе была изложена классификация методов, используемых в системах научных рекомендаций. Каждый подход обладает своими преимуществами и ограничениями, учитывая которые определяются области их эффективного применения. Отмечено, что комбинирование различных алгоритмов позволяет построить более точную систему научных рекомендаций.
Работа выполнена при финансовой поддержке РФФИ (проект №16–29–12875).
Библиографическая ссылка
Мамай И.Б., Ильин Д.А., Лимонова Е.Е., Путинцев Д.Н. СИСТЕМЫ НАУЧНЫХ РЕКОМЕНДАЦИЙ // Международный журнал прикладных и фундаментальных исследований. 2017. № 7-2. С. 181-184;URL: https://applied-research.ru/en/article/view?id=11716 (дата обращения: 04.07.2026).