
Scientific journal
International Journal of Applied and fundamental research
ISSN 1996-3955
ИФ РИНЦ = 0,556
MODEL OF CASE-BASED REASONING SYSTEM FOR FEMALE INFERTILITY DIAGNOSIS

В современных интеллектуальных системах имеются различные подходы к решению задач моделирования человеческих рассуждений. В динамических интеллектуальных системах, в системах экспертного диагностирования, в системах машинного обучения, при поиске решения в малоизученных предметных областях и др. успешно применяются методы индуктивного, абдуктивного выводов [1], а также методы рассуждения по прецедентам (CBR-системы), связанные с накоплением опыта и последующей адаптацией решения известной задачи к решению новой. В современных исследованиях предлагается ряд подходов к интеграции различных типов рассуждений в интеллектуальных системах принятия решений [2; 3, с. 97–109; 4, с. 189–209].
Очевидно, медицина – прецедентная наука, но соответствующий механизм редко используется в медицинской литературе: те или иные ситуационные примеры чаще описываются на основе правил «если – то» или же иллюстрируются деревьями решений. В данной работе основной целью является определение способов представления прецедентов и их извлечения из библиотеки прецедентов (БП) на основе программной системы поддержки врачебных решений, связанной с интеграцией онтологического подхода с другими интеллектуальными технологиями, в частности с методом поиска решений на основе прецедентов (Case-Based Reasoning, CBR). Метод решения возникающих проблем на основе прецедентов (на основе CBR-системы) является наиболее естественным для специалистов, в частности врач, при постановке того или иного диагноза больному, может учитывать аналогичный пример из своего опыта.
В решении задач моделирования человеческих рассуждений, следует отметить, используются разнообразные способы представления прецедентов:
а) представление прецедентов в виде векторов, параметров [5, с. 87; 6, с. 45–57];
б) базы проектных решений (хранилище прецедентов);
в) системы распределенного вывода на основе прецедентов для интеллектуальных систем [7, с.57–62];
г) системы, реализующие прецедентный подход поддержки принятия решений в области медицины (с автоматизированными информационными системами, основанными на аналитической обработке информации для выработки и принятия решений): системы поддержки принятия решений (DiagnosisPro1, IndiGo2, Advisor3);
д) системы вывода на основе прецедентов KATE TOOLS (для выявления сходства между прецедентами используется простая метрика (версия алгоритма ближайшего соседа; DP Umbrella, Apriori);
е) системы, предназначенные для разработки экспертных систем, основанные на прецедентах: CBR Express и CasePoint – обеспечивают ввод, сопровождение и динамическое добавление прецедентов; CASEY (диагностирование сердечной недостаточности); PROTOS (классификация и диагностирование нарушений слуха).
Материалы и методы исследования
Прецедентный подход (метод моделирования рассуждений на основе CBR) дает возможность избегать ограничений, которые свойственны технологиям, использующим модели на основе правил, т.е. решение поставленных задач на основе повторного использования предыдущих (подобных) прецедентов. В настоящей работе для разработки прецедентов используется редактор Protege версии 5. Вначале определяются классы в онтологии и формируются иерархии классов. Корректный анализ прецедентов в системе фреймворка jColibri, как видно из рис. 1, указывает на необходимость создания в OWL-онтологии следующих основных классов: CBR-CASE (экземпляры прецедентов); CBR-DESCRIPTION (ограничения на прецеденты); CBR-INDEX – структура прецедента. Вид бесплодия, как показывает клинический материал, следует определять по следующим параметрам (заболеваниям-прецедентам):
а) гирсутизм (да, нет);
б) дискомфорт в области малого таза (отсутствует, присутствует);
в) мужской тип телосложения (да, нет);
г) наличие бесплодия в семье у родителей (было, не было);
д) наличие хронических заболеваний (одно хроническое заболевание, два хронических заболевания, нет хронических заболеваний);
е) нарушение менструального цикла (нарушен, не нарушен);
ж) нарушение функции щитовидной железы (без нарушений, с значительными нарушениями, с незначительными нарушениями);
з) ожирение (ожирение 1 ст., ожирение 2 ст., отсутствует);
и) патологические процессы (непроходимость маточной трубы, нарушение процесса образования яйцеклеток, образование антиспермальных антител, отсутствие матки, преждевременное истощение функции яичников, физические нарушения в репродуктивной системе).
И в итоге необходимо получить один из диагнозов типа Бесплодия:
1) генетическое бесплодие;
2) иммунологическое бесплодие;
3) психологическое бесплодие;
4) ранний климакс;
5) трубное бесплодие;
6) эндокринное бесплодие.
Описание вышеперечисленных параметров представлено на рис. 1.
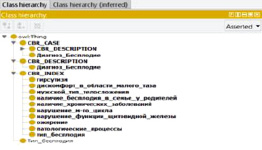
Рис. 1. Структура классов и прецедентов (параметры заболевания)
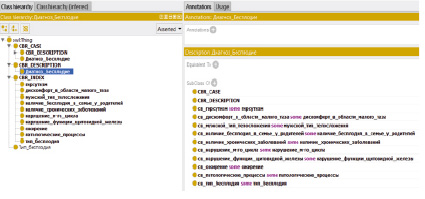
Рис. 2. Объектные отношения между классами
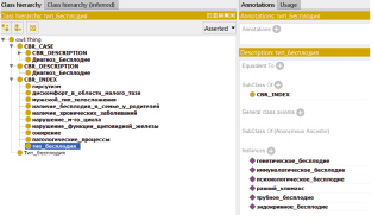
Рис. 3. Экземпляры классов
Рассматриваемая онтологическая модель содержит следующие отношения между классами (см. рис. 2).
Следует отметить, что в описании классов могут быть также использованы конструкты индивидуальностей, где определяется список возможных значений для каждого класса/свойства.
В редакторе Protege для присвоения значения свойствам экземпляров классов предназначена область Property Assertions на странице просмотра экземпляра индивидуального объекта.
Результаты исследования и их обсуждение
Созданная база знаний прецедентов способствует поиску решений в диагностике того или иного вида женского бесплодия, структурировании единицы опыта. В общую структуру прецедента, позволяющую представить процесс решения новой задачи с использованием накопленного опыта, вошли следующие основные составляющие:
а) фиксирующий (диагностирующий) компонент (фиксирует опыт таким образом, чтобы в определенной ситуации лечащий врач оценил бы возможность повторного использования);
б) обучающий компонент – альтернативные решения.
Для обработки прецедентов в OWL-формате (для построения решений, основывающихся на созданной нами онтологии с дескриптивной логикой) использовался набор библиотек бесплатного и свободно распространяемого java-фреймворка платформа jColibri (рис. 4).
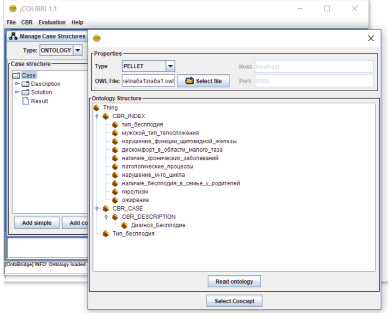
Рис. 4. Структура прецедентов на платформе jColibri
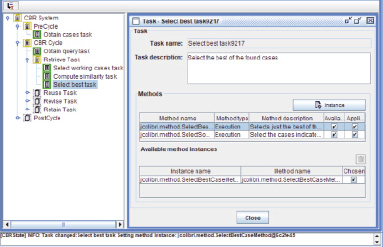
Рис. 5. Результат заполнения дерева
CBR-система запускается после ее настройки на чтение онтологии посредством дескрипционной логики (в итоге получается дерево, изображенное на рис. 5).
После введения параметров, которые пользователь желает получить при помощи в принятии решения, выводится наиболее соответствующий прецедент и отчет, также выводится наиболее подходящий результат, соответствующий запросам, т.е. процессы представляют собой части цикла в базовом виде:
а) retrieve – извлечение прецедентов из Базы знаний методами ближайшего соседа (NN – Nearest Neighbor) на основе ассоциации новой задачи с проблемами, содержащимися в базе прецедентов (принцип «близкие проблемы имеют подобные решения»);
б) reuse – использование информации прецедента в решении поставленной проблемы (часто используется метод адаптации (преобразования) восстановленных решений;
в) revise – оценочный цикл выбранного решения;
г) сохранение (обучение CBR системы), добавление пересмотренного прецедента в базу прецедентов для использования в будущем (retain).
В ходе дальнейшего функционирования CBR-системы возможно ее обучение: количество прецедентов бесплодия увеличивается, что дает возможность данной системе быстро и качественно решать поставленные перед ней задачи, однако CBR-циклы могут потребовать дополнительных временных ресурсов. В данном случае целесообразно оптимизировать работу системы – сократить количество прецедентов на основе методов классификации, кластеризации (разбиения прецедентов на классы семантически близких случаев (кластеры) на основе алгоритмов k-средних, уточняющих границы кластеров прецедентов с целью обобщения накопленной информации (прецедентов) и индексации на основе концептов онтологии, используя евклидову или манхэттенскую метрики или же меры сходств Хемминга, вероятностную меру, Роджерса – Танимото.
Заключение
Сравнение CBR-технологий с другими вычислительными технологиями (в настоящее время решение соответствующих задач отличается многообразием методов, в частности статистический анализ, продукционные системы, машинное обучение и нейронные сети, поисковые системы) позволяет сделать следующие выводы:
а) CBR системы более эффективны в процессе поддержки принятия диагностических решений в экстренных акушерских, гинекологических врачебных ситуациях, чем различные статистические техники, в частности использования индуктивного CBR алгоритма и известного статистического метода под названием линейный дискриминантный анализ;
б) в случае использования CBR-систем нет необходимости в знании, как решается та или иная проблема в определенной ситуации диагностики женского бесплодия: повторно используются предыдущие подобные ситуации, а продукционные системы представляют предметную область в виде множества индивидуальных правил, решающих ту или иную часть задачи;
в) если машинное обучение связано с анализом множества прецедентов и генерацией набора правил, то CBR на основе индуктивных алгоритмов классифицирует существующие прецеденты;
г) нейронные сети оправданы в случаях, где представленные данные не-символы, в частности распознавание речи, а CBR системы лучше работают с соответствующими данными;
д) CBR технологии удобны в определенных модификациях проектной информации интеллектуальных систем в условиях изменившихся требований к формализации онтологических моделей бесплодия.
Применение онтологических баз знаний и инструментальных средств онтологического инжиниринга открывает новые области компьютерной поддержки врачебных решений, упрощает процесс принятия решений в условиях жестких временных ограничений и при наличии различного рода неопределенностей в исходных данных и экспертных знаниях, применении иных метрик при поиске подходящего прецедента для пополнения деревьями решений предметной области как в медицине, так и в других областях знаний. На основе выбранного для анализа подхода можно сформулировать типовой гибридный алгоритм работы системы по диагностированию женского бесплодия.
Библиографическая ссылка
Денисова Е.А., Губанова Г.Ф., Леженина С.В., Чернышов В.В. МОДЕЛЬ СИСТЕМЫ ПОДДЕРЖКИ ПРИНЯТИЯ РЕШЕНИЙ НА ОСНОВЕ РАССУЖДЕНИЙ ПО ПРЕЦЕДЕНТАМ В ОБЛАСТИ ДИАГНОСТИКИ ЖЕНСКОГО БЕСПЛОДИЯ // Международный журнал прикладных и фундаментальных исследований. 2018. № 7. С. 123-128;URL: https://applied-research.ru/en/article/view?id=12340 (дата обращения: 14.07.2026).