
Scientific journal
International Journal of Applied and fundamental research
ISSN 1996-3955
ИФ РИНЦ = 0,556
MODIFICATION OF TINY-YOLO ARCHITECTURE FOR OBJECT DETECTION IN REAL TIME

Во всех современных системах обнаружения на основе компьютерного зрения необходимо не только локализовать местоположение объектов в пределах сцены, но и назначить ту или иную метку класса каждому из них. Самые крупные из недавних успехов в этой области связаны с последними достижениями в области глубокого обучения, в частности с использованием многослойных сверточных нейронных сетей.
До тех пор, пока основной фокус был сосредоточен на улучшении точности, появлялись все более сложные архитектуры, такие как SSD, R-CNN, Mask R-CNN, а также модификации этих сетей [1]. Несмотря на то что системы, в основе которых лежали модели этих сетей, продемонстрировали высокую производительность и качество обнаружения, их было практически невозможно развернуть на портативных и мобильных устройствах из-за ограничений памяти и недостаточных вычислительных мощностей. По сути, даже более быстрые модификации, такие как Faster R-CNN, демонстрировали низкое быстродействие при обнаружении объектов на встроенных процессорах мобильных устройств [2]. Кроме того, такие ограничения помешали широкому распространению сетей для широкого круга приложений, таких как беспилотные летательные аппараты, системы видеонаблюдения, системы автономного вождения, где также требуется локальная обработка. Таким образом, исследование и разработка высокоэффективных архитектур глубоких нейронных сетей для обнаружения объектов, которые больше подходят для периферийных и мобильных устройств, являются актуальной задачей.
Целью исследования является применение принципов проектирования системы обнаружения объектов на основе семейства архитектур YOLO для создания легковесной сети с настраиваемой макро- и микроархитектурой на уровне модулей, адаптированной для задачи обнаружения.
Материалы и методы исследования
Методы глубокого обучения являются более совершенными моделями машинного обучения, обеспечивающими лучшую производительность при решении ряда задач. В то время как традиционные методы машинного обучения занимаются преимущественно ручным извлечением необходимых признаков из доступных входных данных, методы глубокого обучения иерархически извлекают эти признаки и обучаются без учителя или с частичным его участием. На рис. 1 проиллюстрирована структурная схема традиционной модели; схема модели глубокого обучения [3] представлена на рис. 2.
Рис. 1. Структурная схема традиционных методов машинного обучения
Рис. 2. Структурная схема модели глубокого обучения
Глубокое обучение все еще далеко от того, чтобы быть зрелой и хорошо изученной областью, но оно уже используется многими приложениями реального мира, такими как обнаружение и распознавание на основе видения, распознавание и синтезирование речи, энергосбережение, поиск лекарств, финансы и маркетинг. С одной стороны, глубокое обучение предлагает множество возможностей для исследований и эксплуатации, с другой – в глубоком обучении много нерешенных проблем. Это также дает потенциальную возможность первым вывести на рынок разработку, публикацию или некоторый новый продукт в этой области.
YOLO (You Only Look Once) – алгоритм обнаружения объектов в реальном времени. Лежащий в основе YOLO алгоритм принимает в качестве входа исходное изображение или кадр видеопотока один раз, а на выходе возвращает фрагменты этого изображения – каждый участок кадра имеет ограничительную рамку с вероятностью нахождения внутри нее того или иного объекта [4]. Первая версия системы YOLO достигла точности более 50 % для решения задачи обнаружения объектов в реальном времени наборов данных VOC 2007 и VOC 2012, что сделало ее лучшим выбором для этой задачи – как показала практика, YOLO работает гораздо точнее и быстрее, чем любой из алгоритмов, основанных на принципе скользящего окна. Методика модели YOLO основывается только на незначительных изменениях в уже известных алгоритмах.
Отличительной чертой сетей семейства YOLO является то, что, в отличие от так называемых Single-Shot сетей, которые полагаются на построение сетей, предсказывающих местоположение объектов на сцене с их последующей классификацией [4], они используют общую архитектуру для обработки входного кадра и генерации необходимых результатов. Таким образом, все прогнозы выполняются за один прямой проход по сравнению с сотнями и тысячами проходов, которые необходимо выполнить для получения окончательных результатов сетей-предшественников. Это делает архитектуры на основе YOLO значительно более быстрыми и, следовательно, более подходящими для обнаружения объектов различных размеров.
Первоначальный прототип проекта, использованный в этом исследовании, черпает вдохновение из семейства сетевых архитектур YOLO и состоит из стека модулей представления признаков с быстрыми соединениями между модулями. Модули представления признаков конфигурируются способом, подобным сетям пирамид признаков, так что они способны представлять объекты в трех различных масштабах. За этими модулями представления признаков следуют несколько сверточных слоев, выход которых представляет собой трехмерный тензор, кодирующий результат предсказания в виде ограничивающей рамки с принадлежностью к тому или иному классу для трех различных масштабов. В результате такой первоначальный прототип архитектуры позволил обнаруживать многомерные объекты.
Архитектура предлагаемой сети на основе Tiny-YOLO [2] для обнаружения объектов представлена на рис. 3.
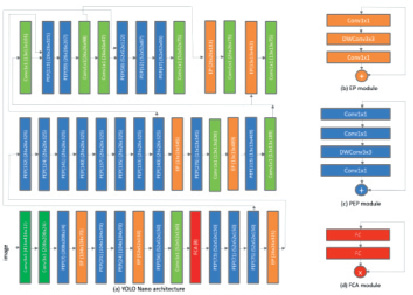
Рис. 3. Архитектура модифицированной сети Tiny-YOLO. Здесь PEP (x) указывает на x каналов в первом слое проекции остаточного модуля PEP, а FCA (x) указывает на коэффициент уменьшения x
Первая особенность архитектуры сети Tiny-YOLO, значительно отличающая ее от семейства других сетей YOLO, заключается в том, что она состоит из модулей с уникальной макроархитектурой на паттерне «проекция – расширение – проекция» (PEP) в дополнение к макроархитектурам «расширение – проекция» (EP). Остаточная макроархитектура PEP состоит из: сверточного слоя со свертками размера 1×1, который преобразует выходные каналы в тензор с более низкой размерностью, слоя расширения со свертками 1×1, который увеличивает количество каналов до более высокой размерности, смещенного вглубь сверточного слоя, который выполняет пространственные свертки с различными фильтрами на каждом из отдельных выходных каналов из слоя расширения, и, наконец, проекционного слоя со свертками 1×1, который конвертирует выходные каналы в выходной тензор с более низкой размерностью. Использование остаточной макроархитектуры PEP позволяет значительно снизить вычислительную сложность при сохранении остальных параметров модели.
Второе значимое наблюдение об архитектуре сети – это введение легковесного модуляционного полносвязного слоя, который состоит из двух полносвязных слоев, изучающих динамические нелинейные взаимозависимости между слоями и создающих веса модуляции для повторного пересчета весов. Использование таких слоев облегчает повторную калибровку динамических признаков на основе глобальной информации, чтобы уделить больше внимания информативным признакам и лучше использовать доступную пропускную способность сети [5]. Это, в свою очередь, позволяет добиться прочного баланса между сниженной архитектурной, вычислительной сложностью и выразительностью модели.
Третье наблюдение касается высокой неоднородности не только макроархитектур (разнообразное сочетание модулей PEP, модулей EP, полносвязных модуляционных слоев, а также отдельных сверточных слоев со свертками 3×3 и 1×1), но также с точки зрения микроархитектур отдельных модулей и слоев представления признаков, причем каждый модуль или слой сети имеет уникальную микроархитектуру. Преимущество высокой неоднородности микроархитектуры в этой модификации Tiny-YOLO заключается в том, что она позволяет индивидуально адаптировать каждый компонент архитектуры сети для достижения сильного баланса между архитектурной и вычислительной сложностью и выразительностью модели.
Результаты исследования и их обсуждение
Чтобы изучить эффективность модифицированной сети Tiny-YOLO для обнаружения объектов в режиме реального времени, необходимо исследовать размер модели, точность обнаружения объектов и вычислительные затраты на наборах данных PASCAL VOC. Для сравнения две существующие и описанные ранее в литературе модификации Tiny-YOLO использовались в качестве базовых. Учитывался тот факт, что они являются одними из самых популярных легковесных глубоких нейронных сетей для обнаружения объектов, небольшие размеры их моделей и низкую вычислительную сложность. Наборы данных VOC2007 / 2012 состоят из полученных в естественной среде изображений с 20 различными типами (классами) объектов. Глубокие нейронные сети были обучены с использованием обучающих наборов данных VOC2007 / 2012, а средняя точность на тестовой выборке (т.е. на не изученных ранее данных) была вычислена на тестовом наборе данных VOC2007 для оценки точности обнаружения объектов глубокими нейронными сетями, что является стандартной практикой в исследовательской литературе.
В таблице показаны размеры моделей и точность обнаружения объектов предлагаемой модификации сети Tiny-YOLO, а также ее ближайших конкурентов Tiny-YOLO 2 и Tiny-YOLO 3.
Cравнение точности обнаружения объектов для основанных на Tiny-YOLO архитектур сетей на тестовом наборе VOC 2007. Размер входных кадров – 416×416 для всех протестированных сетей
|
Название модели |
Размер, Мб |
Точность на наборе VOC 2007, % |
Число операций, млрд |
|
Tiny-YOLO 2 |
60,5 |
57,1 |
6,87 |
|
Tiny-YOLO 3 |
33,4 |
58,4 |
5,52 |
|
Tiny YOLO mod. |
4,0 |
69,1 |
4,57 |
Заключение
В ходе выполнения работы, кроме полноценного анализа предметной области, связанной с данными о компьютерном зрении, машинном и глубоком обучении, были исследованы предшествующие достижения в области задачи обнаружения объектов, в том числе по решению данной задачи другими методами, а также выполнен сравнительный анализ различных модификаций архитектуры Tiny-YOLO, предназначенной для решения задачи, в том числе представленной в работе архитектуры Tiny-YOLO mod.
Как следует из таблицы, описанная в данной работе модель Tiny-YOLO mod. демонстрирует лучшие результаты по всем параметрам.
Во-первых, можно заметить, что размер модели составил 4,0 МБ, что на 15 % и 8 % меньше, чем у Tiny-YOLO 2 и Tiny-YOLO 3 соответственно, что очень важно для периферийных и мобильных устройств с учетом ограничений памяти.
Во-вторых, модифицированная модель Tiny-YOLO, несмотря на то, что она намного меньше по размеру модели в Мб, достигла результата в 69,1 % точности обнаружения объекта на тестовом наборе данных VOC 2007, что приблизительно на 12 % и на 10,7 % больше, чем у Tiny-YOLO 2 и Tiny-YOLO 3 соответственно.
В-третьих, модификация Tiny-YOLO требует всего 4,57 млрд операций для выполнения операции обнаружения и вывода результата на кадр, что на 34 % меньше, чем у Tiny-YOLO 2, и приблизительно на 17 % меньше, чем у Tiny-YOLO 3.
Библиографическая ссылка
Денисенко А.А. МОДИФИКАЦИЯ АРХИТЕКТУРЫ TINY-YOLO ДЛЯ ЗАДАЧИ ОБНАРУЖЕНИЯ ОБЪЕКТОВ В РЕАЛЬНОМ ВРЕМЕНИ // Международный журнал прикладных и фундаментальных исследований. 2021. № 4. С. 53-57;URL: https://applied-research.ru/en/article/view?id=13203 (дата обращения: 05.07.2026).
DOI: https://doi.org/10.17513/mjpfi.13203