
Scientific journal
International Journal of Applied and fundamental research
ISSN 1996-3955
ИФ РИНЦ = 0,556
Dynamic data degradation as a tool to improve the stability of generative-adversarial networks

Введение
Генеративно-состязательные сети (GAN) показывают хорошие результаты в задачах генерации и восстановления визуальных данных, но чувствительны к качеству обучающего набора [1, 2]. Нестабильность GAN при работе с зашумленными, искаженными или нетипичными входами существенно ограничивает применимость моделей в реальных условиях [3]. Один из перспективных подходов к решению этой проблемы – динамическое ухудшение данных «на лету», при котором входные изображения подвергаются искусственным искажениям непосредственно в процессе обучения. Метод позволяет повысить устойчивость модели к шуму, артефактам и нестандартным ситуациям без необходимости расширения датасета.
Рассмотрим влияние on-the-fly деградации данных на устойчивость и обобщающую способность модели SRGAN, являющейся модификацией стандартной GAN, проанализируем типы применяемых искажений, архитектурные особенности обучаемых моделей и метрики оценки качества генерации [4]. Эксперименты показывают, что динамическое ухудшение обучающей выборки способствует формированию более адаптивных признаков, повышая стабильность и точность генерации в условиях деградированных входных данных [5]. Предложенный подход может быть полезен в задачах реставрации изображений, видеоапскейлинга и других направлениях, где важно обеспечение качества при работе с несовершенными данными.
Цель исследования – повышение устойчивости генеративно-состязательных сетей к искаженным и зашумленным входным данным путем внедрения механизма динамического ухудшения данных «на лету» в процессе обучения, оценка влияния рассматриваемого подхода на качество генерации и обобщающую способность моделей в условиях нестабильной входной среды.
Материалы и методы исследования
Разработана методика повышения устойчивости генеративно-состязательных сетей (GAN) за счет применения динамического ухудшения входных данных в процессе обучения. Предложенный подход реализован на базе модифицированной архитектуры ESRGAN, адаптированной для задач суперразрешения и восстановления изображений [6]. Основное внимание уделялось моделированию различных типов деградации, включая гауссовское размытие, шум, JPEG-артефакты и понижение разрешения (downscaling) [7, 8]. Деградация применялась к изображениям низкого разрешения (LR) в случайные моменты обучения, начиная с 100-й эпохи, что обеспечивало постепенное повышение устойчивости модели к разнообразным искажениям. В качестве обучающего набора использовался датасет DIV2K, содержащий 800 пар изображений высокого (HR) и низкого (LR) разрешения. Все изображения масштабировались до размеров 1920×1080 (HR) и 480×270 (LR), нормализовались в диапазоне [−1, 1] и подавались в модель батчами по 2 изображения [9]. Обучение осуществлялось с использованием фреймворка PyTorch и оптимизатора Adam с параметрами [10]:
β1 = 0.9, β2 = 0.99,
learning rate = 2×10–4.
Комбинированная функция потерь генератора [11]:
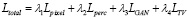 ,
,
где
‒ средняя абсолютная ошибка (L1 loss),
‒ Lpers – перцептивная ошибка, вычисляемая на активациях модели VGG-19,
‒ состязательная потеря (LSGAN),
‒ Total Variation Loss, подавляющая артефакты.
Для оценки качества работы модели использовались метрики:
1. Среднеквадратичная ошибка (MSE) – метрика, измеряющая разницу между значениями пикселей исходного и обработанного изображений. Рассчитывается как среднее значение квадратов разницы между соответствующими пикселями изображения:
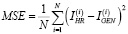 ,
,
где IHR – эталонное изображение, IGEN – результат генерации, N – число пикселей.
Достаточно простая, но эффективная метрика, для которой чем меньше получившееся значение, тем лучше результат. Однако эта оценка не всегда хорошо отражает восприятие человека, так как мелкие, не заметные глазу изменения могут сильно повлиять на конечный результат.
2. Пиковое отношение сигнал/шум (PSNR) – метрика, измеряющая отношение между максимальным возможным значением сигнала (яркости пикселей) и уровнем шума (разницей между исходным и обработанным изображением) [6].
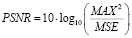 ,
,
где MAX = 1.0 для нормализованных изображений.
Чем выше полученное значение – тем лучше качество изображения. Но, как и в случае с MSE, PSNR не всегда коррелирует с человеческим восприятием.
3. Структурное сходство (SSIM) [6]:
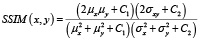 ,
,
где μ, σ – средние и стандартные отклонения по яркости, σxy – ковариация, C1 и C2 – стабилизирующие константы.
Также использовались методы визуальной оценки и сохранения выходных изображений на различных этапах обучения для анализа качества генерации. Все эксперименты проводились с использованием ускорения на GPU и смешанной точности (AMP), что позволило значительно сократить время обучения при сохранении высокой точности вычислений.
Результаты исследования и их обсуждение
Для оценки эффективности предлагаемого метода динамического ухудшения данных «на лету» проведены серии экспериментов, в которых сравнивались версии генеративно-состязательной сети, обученные с использованием деградации и без нее [12, 13]. В качестве контрольных данных использовались изображения из валидационного набора DIV2K, подвергавшиеся разнообразным искажениям, включая гауссовский шум, импульсный шум, размытие и JPEG-артефакты [14]. Результаты выполненных авторами экспериментов приведены в таблице и проиллюстрированы графиками (рис. 1–3).
Сравнение метрик
|
Эпоха |
MSE |
PSNR |
SSIM |
|||
|
Без динамич. дегр. |
С динамич. дегр. |
Без динамич. дегр. |
С динамич. дегр. |
Без динамич. дегр. |
С динамич. дегр. |
|
|
50 |
0,0299 |
0,0297 |
23,9398 |
23,8477 |
0,4426 |
0,4479 |
|
75 |
0,0282 |
0,0281 |
24,0224 |
23,8870 |
0,4891 |
0,4922 |
|
100 |
0,0265 |
0,0294 |
24,9363 |
23,5025 |
0,5208 |
0,4606 |
|
125 |
0,0238 |
0,0217 |
25,0879 |
25,3604 |
0,5570 |
0,6055 |
|
150 |
0,0210 |
0,0176 |
25,7007 |
26,4130 |
0,6018 |
0,6922 |
|
175 |
0,0194 |
0,0139 |
26,1879 |
27,3653 |
0,6244 |
0,7364 |
|
200 |
0,0175 |
0,0103 |
25,8525 |
27,7281 |
0,6739 |
0,7887 |
|
225 |
0,0159 |
0,0070 |
26,5246 |
28,0187 |
0,7171 |
0,8472 |
|
250 |
0,0145 |
0,0066 |
27,1937 |
28,7353 |
0,7465 |
0,8619 |
|
275 |
0,0128 |
0,0057 |
27,4272 |
28,7841 |
0,7875 |
0,9183 |
|
300 |
0,0114 |
0,0053 |
27,5895 |
29,6268 |
0,8242 |
0,9659 |
Источник: составлено авторами.
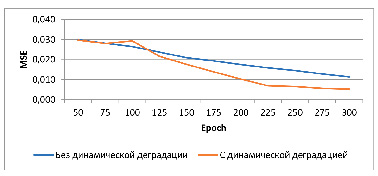
Рис. 1. График сравнения метрики MSE для моделей с динамической деградацией и без нее Источник: составлено авторами
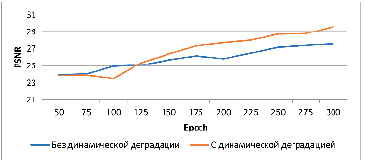
Рис. 2. График сравнения метрики PSNR для моделей с динамической деградацией и без нее Источник: составлено авторами
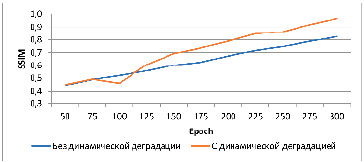
Рис. 3. График сравнения метрики SSIM для моделей с динамической деградацией и без нее Источник: составлено авторами

Рис. 4. Исходное масштабированное изображение Источник: взято из датасета DIV2K
Результаты экспериментов показали, что внедрение on-the-fly деградации повышает устойчивость модели к нестабильным входным данным. В частности, среднее значение метрики SSIM увеличилось на 15 % по сравнению с базовой моделью, обученной на «чистых» данных. Также наблюдалось снижение значения MSE и рост PSNR, что свидетельствует о более точной реконструкции исходных изображений. Было выявлено, что модели, обученные с использованием деградации, демонстрируют лучшую генерализацию при работе с ранее не встречавшимися типами искажений, что проявляется в сохранении структуры и текстур изображения даже при значительных отклонениях от тренировочного распределения. На субъективном уровне результаты генерации таких моделей характеризуются более четкими границами объектов, снижением артефактов и меньшим визуальным шумом.


Рис. 5. Изображения, восстановленные нейросетью, слева модель без деградации данных, справа – с деградацией Источник: получено авторами в результате проведенного исследования
Отметим, что эффект устойчивости не был достигнут ценой существенного роста вычислительной сложности. Благодаря постепенному включению ухудшений в ходе обучения (начиная с 100-й эпохи) модель имела возможность сначала выучить базовые закономерности, а затем адаптироваться к сложным условиям, что позволило избежать проблем переобучения и сохранить стабильность процесса оптимизации. С результатом работы моделей с деградацией данных и без ее использования можно ознакомиться на рис. 4–5.
Таким образом, предложенный подход на основе динамической деградации данных в процессе обучения подтверждает возможность использования на практике, как инструмент повышения устойчивости GAN к реальным искажениям. Метод может быть полезен в задачах, связанных с реставрацией, суперразрешением и генерацией изображений в нестабильных или ограниченных по качеству условиях [15]. Видится перспективным дальнейшее исследование по расширению использования рассмотренного подхода, включая его адаптацию к видео-данным и применению в мультимодальных генеративных архитектурах [16].
Заключение
Результаты проведенного исследования подтвердили эффективность метода динамического ухудшения данных «на лету» для повышения устойчивости генеративно-состязательных сетей. Введение искажений в процессе обучения позволило добиться значимых улучшений по ключевым метрикам качества (MSE, PSNR, SSIM), что свидетельствует о более точной реконструкции изображений и снижении визуальных артефактов. При этом подход не потребовал существенного увеличения вычислительных ресурсов, благодаря поэтапному включению деградаций, начиная со 100-й эпохи обучения.
Особый интерес представляет выявленная способность моделей, обученных с деградацией, успешно обрабатывать ранее не встречавшиеся искажения, что указывает на рост обобщающей способности и адаптивности архитектуры. Это открывает перспективы применения метода в условиях ограниченного или нестабильного качества данных, таких как восстановление поврежденных изображений, апскейлинг в режиме реального времени и медицинская визуализация.
Таким образом, динамическое ухудшение данных может быть рекомендовано как надежный и универсальный механизм повышения устойчивости GAN в прикладных задачах. В дальнейшем представляется целесообразным расширение подхода на видеоформаты, а также исследование его эффективности в рамках мультимодальных генеративных моделей.
Conflict of interest
Библиографическая ссылка
Ананченко И.В., Добровольский Д.К., Уруймагов Я.Г. Динамическое ухудшение данных как инструмент повышения устойчивости генеративно-состязательных сетей // Международный журнал прикладных и фундаментальных исследований. 2025. № 8. С. 46-51;URL: https://applied-research.ru/en/article/view?id=13745 (дата обращения: 01.07.2026).
DOI: https://doi.org/10.17513/mjpfi.13745