

Введение
В настоящее время многие исследователи применяют компьютерный анализ текстов для решения различных задач при работе с неструктурированными текстами, в том числе в медицине [1-3]. Исследуются возможности методов обработки естественного языка для решения широкого спектра задач: скрининга заболеваний [4], определения диагноза [5, 6], улучшения наблюдения за пациентами [7], изучения жалоб пациентов, исправления ошибок в тексте [8] и т.д. Разработаны модели для работы с русскоязычными медицинскими текстами [9].
Несмотря на значительный интерес к алгоритмам извлечения информации из текста на нейросетей [4, 8], сохраняют свою актуальность и более традиционные методы, требующие предварительной обработки данных с последующим анализом n-грамм, применением логистической регрессии и др. [5]. При этом большинство авторов комбинируют традиционные и нейросетевые алгоритмы [10–13].
Несмотря на возросшее количество публикаций, посвященных этой теме в последние годы, методы машинного анализа текста остаются относительно недооцененным в профессиональной медицинской среде [14, 15]. При этом самой текстовой информации становится больше, а возможности ее получения за счет распространения социальных сетей и цифровизации здравоохранения становятся менее ресурсозатратными [15].
Исходя из этого, освоение методов машинного анализа текста представляет собой перспективное направление, особенно в условиях растущего объема доступной текстовой информации.
Цель исследования: привлечь внимание российских исследователей к этим инструментам. Для этого авторы хотели бы представить вниманию коллег собственный опыт и таким способом продемонстрировать относительную простоту этих методов и возможности их применения.
Материалы и методы исследования
В рамках данного исследования проанализированы эссе клинических ординаторов первого года ФГБУ ГНЦ ФМБЦ им. А.И. Бурназяна, проходивших обучение на цикле по патологии в 2021–2022 гг., на тему «Почему я не патологоанатом?». Всего было получено и проанализировано 297 эссе, среднее значение количества слов в эссе составило 422, минимальное и максимальное значение соответственно 57 и 1063 слова, медиана – 424 слова.
В настоящей работе представлен комплексный анализ текстовых данных, который состоит из двух основных частей. В первой части реализована численная характеризация текстов с использованием методов нейросетевого анализа без предварительной обработки текстов. Вторая часть исследования фокусируется на лингвистическом анализе текстов, который включает в себя выявление n-грамм, создание облаков слов и последующий семантический анализ этих данных с целью формирования представления о содержательных аспектах исследуемых текстов. Описание методологических подходов, а также примеры и выводы, сформулированные на основе проведенного анализа, изложены ниже.
Результаты исследования и их обсуждение
Авторы провели сравнение текстов на предмет антиплагиата с использованием современных методов анализа текста на основе модели глубокого обучения word2vec [16], позволяющей переводить строковые данные в числовые представления. Такое преобразование позволяет применить арифметические операции к текстовым данным [17]. Для получения численных представлений использовалась предобученная модель семейства MPNet [18], поскольку в сравнении с аналогами она демонстрирует высокую эффективность при работе с текстами. Численные векторы, полученные через использование алгоритма нейросетевого глубокого обучения, служат отправной точкой для ряда последующих аналитических методов, таких как кластеризация и анализ на антиплагиат. Эти векторы, сгенерированные с высокой точностью и скоростью, могут быть легко интегрированы в различные системы анализа данных, обеспечивая тем самым повышенную точность и снижение временных затрат на обработку больших текстовых массивов.
Проверка эссе на наличие плагиата
Для выявления плагиата применялась общеизвестная (стандартная) методика, описанная во множестве работ, опубликованных в последние годы [19, 20]. Метод подразумевает сравнение векторов друг с другом по косинусному расстоянию. Диапазон метрики варьируется от 0 до 1, где 0 – это не имеющие ничего общего данные, а 1 – это одинаковые данные. Пороговое значение, по которому выделяются похожие тексты, в рамках данной работы было определено эмпирически и составило 0,95. На рисунке 1 приведена тепловая карта, построенная на основе данных о схожести численных представлений эссе, где, в частности, видно, что у текстов под номерами 150 и 194 значение схожести близко к 1. На рисунке 2 приводятся фрагменты текстов этих эссе.
Кластеризация
Численно представленные векторами тексты могут быть проанализированы стандартными статистическими методами. В данной работе был использован метод кластеризации с целью создания групп сходных объектов (кластеров). Для кластеризации использовались алгоритмы агломеративной кластеризации и KMeans [21].
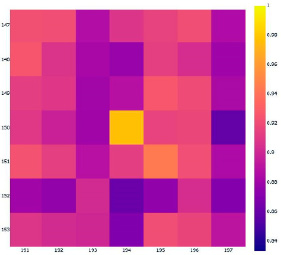
Рис. 1. Фрагмент тепловой карты с высоким значением косинусного расстояния на пересечении наблюдений 194 и 150

Рис. 2. Фрагменты текстов эссе № 150 и № 194
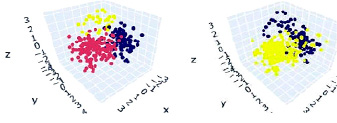
Рис. 3. Кластеризация отдельных эссе. Слева представлена кластеризация по алгоритму KMeans, справа – по агломеративному алгоритму
Кластеризация осуществлялась в двух вариантах: на основе отдельных эссе студентов и на основе текстов, объединенных по специальностям. В полученных по результатам анализа кластерах не удалось выявить сколько-нибудь значимую связь со специальностями авторов, как для отдельных эссе, так и при анализе их групп. На рисунке 3 представлены результаты кластеризации, спроецированные на трехмерное пространство с помощью метода главных компонент.
Анализ текст по n-граммам Предварительная обработка корпуса данных
Предобработка текста включала в себя следующие элементы: лемматизация, удаление стоп-слов и небуквенных символов; операция лемматизации с помощью библиотеки pymystem3; удаление стоп-слов с помощью библиотеки nltk, расширенной с учетом специфики данных следующими терминами: «специальность», «профессия», «патологоанатом», «врач», «человек», «работа», «медицинский», «университет», «патологический», «анатомия». Удаление небуквенных символов произведено с помощью стандартной библиотеки для регулярных выражений в Python. По результатам предварительной обработки получены «очищенные» тексты, избавленные от нерелевантных стоп-слов, вспомогательных слов и небуквенных символов. Эта оптимизированная форма текста облегчает проведение последующих этапов анализа и улучшает качество семантического анализа.
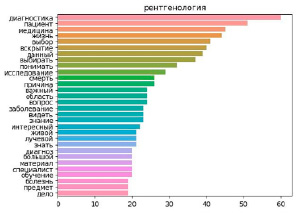
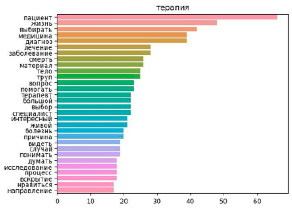
Рис. 4. Столбчатые диаграммы частот юниграмм в наиболее представительных группах диагностических («Рентгенология», 33 наблюдения) и клинических («Терапия», 27 наблюдений) специальностей
Анализ частотности n-грамм
Анализ частотности n-грамм позволяет изучить распределение и взаимосвязь последовательностей из n слов в тексте, что поможет выявить ключевые понятия и дать представление об общей концепции анализируемого текста [22]. Были использованы три варианта n-грамм: юниграммы, биграммы, триграммы, содержащие соответственно одно, два и три слова. Среди наиболее частых юниграмм выявлены следующие слова: «пациент», «жизнь», «вскрытие», «смерть», «диагноз», «труп», «лечение».
Это позволило сформировать общее представление о содержании текста. Кроме этого, были выявлены различия в частотах слов по группам специальностей. Слова «жизнь», «помощь» и «общение» занимали более высокий ранг в терапевтических и хирургических специальностях, в эссе диагностических специальностей термин «аутопсия» занимал более высокий ранг. Наиболее частые юниграммы для специальностей «Рентгенология» и «Терапия» приведены на рисунке 4.
Анализ биграмм позволил уточнить предположения, полученные при анализе юниграмм. В частности, юниграмма «смерть» с высоким рангом во всех группах при анализе биграмм оказалась составным элементом «причина смерть», т.е. с большей вероятностью связана с темой эссе, чем с личными причинами невыбора специальности. Юниграмма «пациент» распределилась по нескольким биграммам: с высокими частотами «общение пациент» и «жизнь пациент» и более редкие «смерть пациент» и «живой пациент». При этом частоты самых популярных биграмм во всем корпусе данных исчислялись десятками, что группировку эссе по каким-либо признакам и последующий их анализ. Тридцать наиболее частых биграмм во всем корпусе данных приведены на рисунке 5.
Анализ триграмм в значительной степени дублировал наблюдения, обнаруженные при анализе биграмм, при этом акцент в большей степени сместился к психологическим аспектам работы и к необходимости взаимодействовать с биологическим материалом как источником профессионального риска. При этом наиболее распространенные триграммы по своим частотам находились в диапазоне одного-двух десятков, что в еще большей степени ограничивало возможность их применения для межгруппового анализа. Увеличение количества эссе, как и в случае с биграммами, позволило бы обойти это ограничение, однако первичные данные в таком случае должны были бы исчисляться тысячами наблюдений. Наиболее частые триграммы представлены на рисунке 6.
Облако слов
Из-за ограниченного объема данных инструмент «облако слов» применяли только к юниграммам. Облако слов – это визуальное представление списка категорий, при котором частота каждой категории выражается размером шрифта или цветом [23].
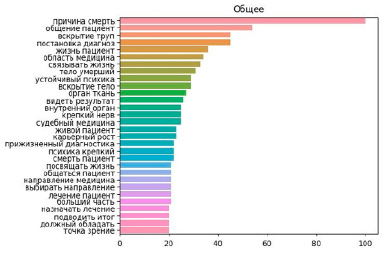
Рис. 5. Столбчатая диаграмма частот биграмм в корпусе данных
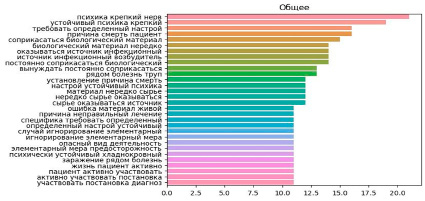
Рис. 6. Столбчатая диаграмма частот триграмм в корпусе данных

Рис. 7. Облако слов, составленное для всего корпуса данных
Такое представление удобно для быстрого восприятия и для распределения терминов по популярности друг относительно друга, что, по мнению авторов, делает его удобным инструментом для ориентировочного анализа. Для построения облака слов использовалась библиотека wordcloud языка программирования Python.
Обсуждение
Проведенный в настоящей работе анализ неструктурированных текстов различными автоматизированными методами позволил сравнить их эффективность для раскрытия семантического содержания эссе.
Нейросетевые алгоритмы были успешно применены для численного представления и поиска схожих по содержанию текстов – анализа на антиплагиат. Были выявлены тексты различной степени схожести, вплоть до полной идентичности. Этот подход позволил во всем массиве текстов быстро и с минимальными затратами ресурсов найти работы, которые с высокой вероятностью были написаны одним автором.
Несмотря на широкое применение метода кластеризации в анализе неструктурированных текстов [24], в рамках данного исследования с его помощью не удалось обнаружить значимых связей. Скорее всего, такой результат связан с тем, что анализируемые тексты принадлежат одной тематической области и были созданы сравнительно однородной группой авторов.
Помимо современных нейросетевых методов, классические подходы сохраняют свою актуальность. Анализ частотности n-грамм является широко используемым в аналитической практике. По результатам данного исследования наибольшую информативность продемонстрировали биграммы. В сравнении с юниграммами и триграммами биграммы обеспечивали наилучшее соотношение между числом упоминаний и семантической насыщенностью, становясь, таким образом, «золотой серединой». Графические методы, такие как столбчатые диаграммы и облака слов, делают этот анализ более наглядным для исследователя.
Заключение
Применение нейросетевых моделей при анализе текста было наиболее эффективным для численного представления анализируемого текста и поиска плагиата среди эссе. Вероятно, из-за относительно малого объема первичного материала и узконаправленной темы использование результатов нейросетевого анализа для кластеризации оказалось неэффективным.
Применение традиционных методов анализа, требующих предварительной подготовки корпуса данных и базирующихся на вычислении частот n-грамм и построении облака слов, позволило более детально изучить смысловую часть текстов в их общем представлении и выделить особенности для различных специальностей или их групп.
Библиографическая ссылка
Меликбекян А.А., Борбат А.М., Новикова Т.О., Павлов К.А. Исследование содержания медицинских эссе: нейросетевые подходы и традиционные методы // Международный журнал прикладных и фундаментальных исследований. 2024. № 6. С. 25-31;URL: https://applied-research.ru/ru/article/view?id=13640 (дата обращения: 01.07.2026).
DOI: https://doi.org/10.17513/mjpfi.13640